


Olá Pessoal, tudo bom?
Há 3 anos atrás construí uma serie de artigos sobre versionamento de Projetos de Software, mas nunca mais mudei esses artigos ou acrescentei coisas novas. Para ver todos os artigos sobre versionamento acesse esta página. Lá haverá um mapa mental com todos os artigos. Nesse artigo vamos explorar o que é controle de versão de projetos e porque isso é tão importante para o desenvolvimento de um projeto. Veja na continuação.
Versionamento
Quantos desenvolvedores que você conhece, inclua-se nessa conta, que fazem backup do código fonte de suas atividades e projetos de software? E desses desenvolvedores que fazem backup, quais deles mantém várias versões dos seus códigos, desde as primeiras linhas criadas em um projeto? Controle de versão com o comando UNDO (Ctrl + Z) não vale! 🙂
E quando a construção de um projeto de software é realizada por uma equipe de desenvolvimento, existe um mecanismo de backup dos códigos? Ou ainda, quantas vezes um código que foi codificado por você, deixou de existir porque alguém apagou o código, podendo até ser erroneamente?
Com essas perguntas simples é possível perceber que versionamento de um projeto de software deve ser uma premissa, não algo a ser pensado no futuro. Ou seja, é muito importante confiar em uma ferramenta que possua um histórico de edição de todos os arquivos de um projeto, indicando algumas características como por exemplo:
- Qual desenvolvedor realizou a alteração
- Data que a alteração foi realizada
- Pontos do código que foram alterados
- Motivo do desenvolvedor realizar essa alteração
Tudo isso pode parecer novo, principalmente se você estiver dando os primeiros passos no mundo do desenvolvimento de software, mas atire a primeira pedra quem nunca guardou o projeto zipado como versão de código, e, ao fim do trabalho de um dia, guardava uma nova versão desse arquivo zip, mandando por email, armazenando em algum drive na nuvem ou pior ainda, em um pen drive.
OK. Mas durante esse novo desenvolvimento não houveram mudanças, como criações de classes novas? Exclusão de códigos? Exclusão de classes? Onde esse conhecimento ficou guardado? Ou se for necessário retomar um código, como será feita essa busca?
Assim o versionamento é algo muito mais profundo. Se levado com seriedade pode mostrar a história da evolução de um projeto de software, desde a sua primeira classe! Pois a cada fim de dia de trabalho, ou finalização de algo importante, o desenvolvedor subir, commitar, os arquivos de ele alterou para o versionador, estes estarão disponíveis para todos os outros desenvolvedores da equipe baixarem.
Conceitos Básicos – Commits e Merges
Nesse tópico serão descritos alguns conceitos básicos sobre versionamento. Primeiramente pense nos conceitos de estruturas de dados, para melhor entendimento, como por exemplo em árvores binárias, como a Figura 01 abaixo:
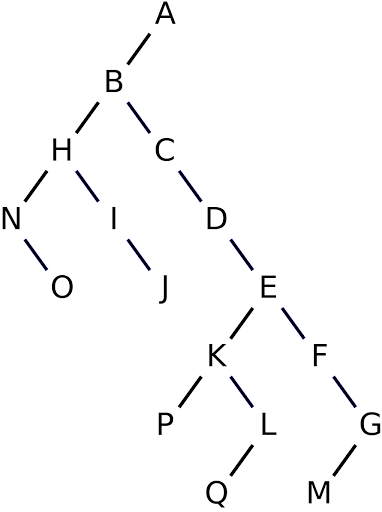
Existe sempre uma raiz, no caso da figura o ponto A, e depois deste ponto vão surgindo novos pontos, chamados de nodos. Suponha que para cada uma dessas letras foi realizado um upload de código, commits, realizados por desenvolvedores na ferramenta de versionamento. Agora vamos inserir uma linha do tempo de cima para baixo, Figura 02, indicando que nunca um nodo que está embaixo foi commitado antes do nodo superior.

Imaginemos então que o código foi tomando forma, em várias frentes, conforme o tempo foi passando. Mas há um ponto muito importante, essa estrutura de dados não contém unificações, ou seja, não existe a junção de dois ramos mas somente vários ramos separados um dos outros. Dessa forma, o código criado por vários desenvolvedores nunca será reunido e então não haverá apenas 1 software!
Muito provavelmente haverão N softwares ao fim do ciclo de desenvolvimento. E isso não é o desejado. Assim vamos dar um nome para essa operação de união de códigos, ela é chamada de Merge. Para atender a essa necessidade de haver várias operações de merge, durante o desenvolvimento de um software será necessário mudar a estrutura de dados de nosso exemplo para um grafo, Figura 03.

Conceitos Básicos – Head e Branches
Outro trabalho que iremos realizar é a de elencar um ramo principal da estrutura, onde para esse ramo todos os outros ramos irão realizar a operação de merge um dia . Isso acontece porque durante o ciclo de vida de um software existe um fase que o software passará a ser utilizado pelo cliente final, indo para a Produção, como é padrão de ser dito. Assim para facilitar a padronização dos nomes, esse ramo principal que iremos selecionar é chamado de Head.
Suponha que seu cliente pede uma alteração grande no software que já está em produção. Não podemos sair alterando o código que está no Head, sem correr riscos de criar novos erros ou problemas em funcionalidades já existentes. Para construir essa nova alteração existe o caminho de criação de um branch. Cada branch é um ramo secundário, ou seja, um ramo que foi criado a partir do código existente de um determinado ponto do head, ou de outro ramo secundário, e o desenvolvimento continuou a partir desse ponto. Vamos atualizar o nosso exemplo com essas novas informações, Figura 04.

Assim é fácil perceber que as linhas na cor azul representam o Head, ou seja, o ramo principal, o código do software em produção. As linhas na cor preta representam os ramos secundários, ou seja, ramos que foram criados para realizar alterações que o cliente do software deseja. E as linhas de cor laranja representam operações de Merge, reunindo o código de dois branches ou o código de um branch com o head.
Agora uma questão. O que representam os pontos C, D, E, F, G, M?
Se você respondeu, representam modificações realizadas no código em Produção está correto!
Epa! Peraí! Você acabou de mencionar que o código da Head não deve ser alterado sem ser criado um novo branch e agora você fala que foram realizadas alterações no Head? Não entendi nada!
Realmente é necessário criar um branch a parte para trabalhar com alterações grandes pedidas pelo cliente. Mas e se houver erros? Por exemplo, foi identificado pelo cliente um erro em produção e aí? Onde será realizada a modificação do código? Como para esse tipo de caso é necessário que o erro seja corrigido rapidamente e seja feito um deploy (substituição) da nova versão em produção, essa alteração é realizada no Head, pois após o novo deploy a ultima versão do Head deverá contemplar o estado que a produção se encontra, ou seja, com a correção do erro. Por isso os pontos citados acima!
finnaly{
Para subir um código para o versionador é realizada uma operação de Commit. Para obter a ultima versão do código do versionado é realizada uma operação de Pull, o qual representa o download do código que está no versionador. Merge é a operação mais crítica de um versionamento, pois realiza a união de códigos de dois pontos do versionador, normalmente o local, do desenvolvedor, e o remoto do versionador. Todas as alterações podem ser realizadas no Head ou em Branches secundários.
Existem diversas ferramentas de versionamento disponíveis para ser utilizada por desenvolvedores. Hoje com o advento da computação em nuvem, não é necessário mais ter um servidor instalado para realizar isso, pois há serviços on line que disponibilizam versionadores para serem utilizados. Mas isso é discussão para um próximo artigo.
Duvidas ou sugestões? Deixe seu feedback! Isso ajuda a saber a sua opinião sobre os artigos e melhorá-los para o futuro! Isso é muito importante!
Até um próximo post!
Oi Maudinha, td bem? Que show, encontrei seu blog por acaso! Muito legal! Parabéns por estes trabalho!
Olá Cezar, tudo bom?
Valeu! 🙂 Espero ter ajudado nas suas duvidas!
Precisando estamos por aqui!
Obrigado.