


Olá Pessoal, tudo bom?
No artigo de hoje iremos descrever um pouco sobre o Html DOM, ou Html Document Object Model que nada mais é que uma estrutura de dados do tipo árvore que abriga todas as tags de um documento de markup language como o HTML ou XML.
O que é DOM?
O Document Object Model é uma interface neutra, independente de plataforma ou linguagem, que permite a programas ou scripts acessar dinamicamente o conteúdo, estrutura e estilo de documentos. O documento pode ser processado posteriormente e o resultado deste pode ser incorporado na página em apresentação. ((What is the Document Object Model? – link))
Assim o DOM apresenta um documento HTML como uma estrutura de dados do tipo Arvore (Tree). Resumindo o DOM é um padrão para auxiliar como obter, mudar, adicionar ou deletar elementos de um documento HTML. Cada elemento é chamado de node-tree.
Node Tree
O Html DOM auxilia a representação do documento HTML. Como é representado em forma de árvore, a partir de sua raiz, qualquer nodo pode ser acessado. Observe o código HTML abaixo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
<html> <head> <title>Documento HTML Teste</title> </head> <body> <form id="j6"> <div id="j6:j7"> <div id="j6:j7_header"> Documento HTML Teste </div> <div id="j6:j7_content"> <button id="j6:j9" type="submit"> Pesquisar </button> </div> </div> </form> </body> </html> |
Esse código irá gerar a tela descrita na Figura 01, a partir do parser em um browser:

NODES
Em uma árvore, os Nodos (Nodes) possuem uma relação hierárquica entre si. Assim as seguintes afirmações são verdadeiras:
- Em uma arvore, o nodo do topo, nodo raiz, é chamado de Root Node
- Cada nodo, exceto o Root, possui exatamente um nodo pai (Parent Node)
- Um nodo pode possuir qualquer número de nodos filhos (Child Node), até mesmo zero
- Um nodo que possua zero nodos filhos, ele é chamado de nodo folha (Leaf Node)
- Nodos irmãos (Siblings Nodes) são nodos que possuem o mesmo pai
A Figura 02 representa uma parte da arvore apresentada na Figura 03, com os relacionamentos entre os Nodos.
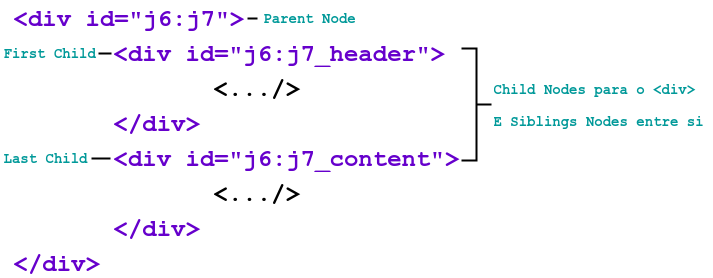
Assim o código irá gerar a arvore DOM representada na Figura 03:

Dessa Figura 03 podemos obter as seguintes afirmações:
- O node <html> não possui Parent Node, sendo chamado de Root Node
- O node <html> possui dois Child Nodes, <head> e <body>
- Os nodes <head> e <body> possuem como Parent Node o node <html>
- Os nodes <head> e <body> são Siblings Nodes
- O node <head> possui um Child Node, o node <title>
- O node <title> possui um Child Node, o node texto “Documento HTML Teste“
- O node texto “Pesquisar” possui como Parent Node o node <button>
Outras Tecnologias
Nem sempre escreveremos um código puramente em HTML (Se torna muito improdutivo fazer esse tipo de coisa). Assim existem diversas, inúmeras, tecnologias que trazem componentes codificados em algo parecido com HTML. Somente citando o mundo Java, temos Java Server Pages, Java Server Faces, Struts, Spring como as mais famosas.
O que todas essas tecnologias possuem em comum? Dentro destas existe um “Parser”. Ou seja, de um conversor que obtém esse código próprio da tecnologia, criado pelo desenvolvedor, com todos os componentes e recursos que essas bibliotecas possuem, e gera um código HTML que pode ser interpretado por qualquer browser, sem maiores problemas. E como é um documento HTML ele irá gerar essas informações no padrão DOM.
Assim por mais que possa parecer simplório esse artigo, ele vem elucidar algo muito básico, que é a estruturação do código HTML que será interpretado pelo browser. Assim ao combinar outros aspectos das bibliotecas podemos ocasionar erros que podemos não entender o que está ocorrendo senão observarmos esse padrão, principalmente quando um desses aspectos é o AJAX.
finnaly{
Esse é um artigo base para ajudar nas explicações de outros artigos, assim estarei utilizando deste quando estiver tratando sobre erros na Árvore DOM.
Duvidas ou sugestões? Deixe seu feedback! Isso ajuda a saber a sua opinião sobre os artigos e melhorá-los para o futuro! Isso é muito importante!
Até um próximo post!
Leave a Reply